idea, data, solution, std from csy2005
算法负二
对于特殊性质 A,长度为 $l$ 的元素互不相同的序列的本质不同子序列数为 $2^l$,只有当 $l=0$ 时为奇数。故 $(x,y)$ 合法的充要条件为 $x=y$,答案为 $n$。
可以通过子任务一,期望得分 $5$ 分。
算法负一
对于特殊性质 B,长度为 $l$ 的元素全部相同的序列的本质不同子序列数为 $l+1$。故 $(x,y)$ 合法的充要条件为将树黑白染色后,$x$ 和 $y$ 同色。答案为黑点个数平方加白点个数平方。
可以通过子任务二,结合算法负二期望得分 $10$ 分。
算法零
根据题意模拟,枚举每一对 $(x,y)$,再枚举这条链的每个子序列,把它们插进 std::set 里判断奇偶性即可。
时间复杂度为 $O(2^n\times \text{poly}(n))$,可以通过子任务三,结合算法负二、算法负一期望得分 $15$ 分。
算法一
考虑怎么求一个给定的序列 $a$ 的本质不同子序列个数。
为了避免算重,对每个本质不同子序列,我们只在其最后一次在原序列中出现时计算它。
记 $f_{i,j}$ 表示考虑序列的前 $i$ 个元素,以元素 $j$ 结尾的本质不同子序列个数。
当 $j=a_i$ 时:
$$f_{i,j}=1+\sum_{1\leq k< n}f_{i-1,k}$$
当 $j\neq a_i$ 时:
$$f_{i,j}=f_{i-1.j}$$
总共的本质不同子序列数即为 $1+\sum_{1\leq i< n} f_{n,i}$。
对于子任务四,枚举 $x$ 从左往右扫维护 dp,即可求出每一对 $(x,y)$ 的答案。
时间复杂度为 $O(n^3)$,可以通过子任务四,结合算法负二、算法负一、算法零期望得分 $35$ 分。
算法二
考虑把算法一放到树上。
枚举 $x$,以 $x$ 为根进行 dfs,每次记录下从 $x$ 到当前点的路径中每个前缀的 dp 值,结束对一个点的 dfs 时把它的 dp 值扔掉即可。
时间复杂度为 $O(n^3)$,可以通过子任务五,结合算法负二、算法负一期望得分 $40$ 分。
算法三
发现实际上每次在序列末尾插入一个元素时,$f_i$ 和 $f_{i-1}$ 实际上只有一个元素有区别。考虑使用滚动数组优化这个 dp。
由于是树而不是链,我们仍需支持 dp 值的回退。但由于每访问一个点只修改一个值,我们只需记录这个值原来是多少即可,而无需记录整个 dp 数组。
时间复杂度为 $O(n^2)$,可以通过子任务六,结合算法负二、算法负一期望得分 $50$ 分。
算法四
我们还没有用到只需求出本质不同子序列个数的奇偶性而不是具体值这个性质。
观察我们刚才的 dp。记 $f_{i,0}=1+\sum_{1\leq j< n}f_{i,j}$。答案就是 $f_{n,0}$。
考虑新增一个值 $a_i$ 的影响。
$$f_{i,a_i}=1+\sum_{1\leq k< n}f_{i-1,k}=f_{i-1,0}$$
$$f_{i,0}=1+\sum_{1\leq j < n}f_{i,j}=1+\sum_{1\leq j < n,j\neq a_i}f_{i-1,j}+f_{i-1,0}=2f_{i-1,0}-f_{i-1,j}$$
而 $2f_{i-1,0}-f_{i-1,j}$ 与 $f_{i-1,j}$ 的奇偶性相同。
也就是说,新增一个值 $a_i$ 就相当于交换了 dp 数组中下标为 $0$ 的位置和下标为 $a_i$ 的位置的值!
初始时,$f_{0,j}=[j=0]$。于是任意时刻,dp 数组中正好有一个奇数,一个序列的本质不同子序列个数为奇数,当且仅当最终这个奇数在下标 $0$。
于是我们就有了一个暴力做法,每次枚举 $x$ 开始 dfs,dfs 时维护当前奇数在哪个下标。
时间复杂度为 $O(n^2)$,和算法三相同,可以通过子任务六,结合算法负二、算法负一期望得分 $50$ 分。但这个算法显然更有前途。
算法五
由算法四中的结论可以得出,一个序列的本质不同子序列个数为奇数,当且仅当它可以划分为若干个长度至少是 $2$ 的子串,使得每个子串的开头和结尾的数相同,且这个数没有在子串中其它位置出现过。我们称每个这样的子串为极短合法序列。
考虑点分治。对于每一层,从分治中心开始 dfs,对每个点,求出其到分治中心的路径经过尽可能地删去是极短合法序列的前缀后,剩下的串的开头(或者这个串被删空)。对于两个在不同子树中的点,合法当且仅当它们剩下的串的开头相同或它们均被删空。
时间复杂度为 $O(n\log n)$,可以通过子任务七,期望得分 $65$ 分。
算法六
我们发现,$(x,y)$ 合法这种关系是一个等价关系。即满足自反性($(x,x)$合法),对称性($(x,y)$ 和 $(y,x)$ 合法性相同),传递性(若 $(x,y)$、$(y,z)$ 均合法则 $(x,z)$ 合法)。
自反性和对称性是显然的,以下是传递性的证明:
根据算法五开头的判定方式,合法序列的拼接是合法序列,从合法序列中去掉一个合法的前/后缀得到的是合法序列。
设路径 $(x,y)$ 和路径 $(y,z)$ 的交是路径 $(y,u)$,$(x,u)$ 的极长合法前缀是 $(x',u)$,$(y,u)$ 的极长合法前缀是 $(y',u)$,$(z,u)$ 的极长合法前缀是 $(z',u)$。
若 $y'=u$,即 $(y,u)$ 本身合法,那么 $(x,u)$、$(u,z)$ 均是合法的,所以 $(x,z)$ 是合法的。
否则 $(x',y')$、$(z',y')$ 均是合法序列,于是得到 $(x'->u)$ 路径上的第一条边、 $(y'->u)$ 路径上的第一条边、 $(z'->u)$ 路径上的第一条边的边权均相等,且这三条路径上没有其他边的权值和它们相等,于是 $(x',z')$ 是合法的,那么 $(x,z)$ 也是合法的。
于是我们只需尽可能得合并等价类,然后计算每个等价类大小的平方和。
首先进行第一轮合并。考虑一个点 $x(x>1)$,若 $f_x$ 的祖先中存在边权与 $a_x$ 相同的边,找到与 $f_x$ 最近的边 $(y,f_y)$,那么 $(x,y)$ 是合法的,可以把 $x$ 和 $y$ 合并到一个等价类中。
第一轮合并后,令每个等价类中最浅的点为这个等价类的代表(显然唯一),那么每个代表 $x$ 都满足 $f_x$ 的祖先中不存在边权与 $a_x$ 相同的边。根据这个性质,我们发现对于两个代表 $x,y$,$(x,y)$ 合法当且仅当 $x\neq 1,y\neq 1,a_x=a_y$。于是我们可以再进行第二轮合并,把所有 $a$ 相同的等价类合并起来。第二轮合并后属于不同等价类的 $x,y$ 一定两两不合法。
实现时,我们通过自顶向下的 dfs 可以直接计算出每个点属于哪个等价类,故不需要使用并查集之类的数据结构来维护。
时间复杂度为 $O(n)$,可以通过所有子任务,期望得分 $100$ 分。
idea, data, solution, std from Sooke, solution2 from 127
题外话
出题人自以为设置了良心的部分分,未顾虑到临场选手的时间安排,对造成的不佳体验实感抱歉!
本题背景是抽芽游戏的变种 Planted Brussels Sprouts。鄙人不通现代处理技巧,仅给出些许古老但巧妙的推法,并不代表本题局限于此,请诸位尽情各显神通。
算法一
把题目的计数拆成两部分,我们相当于求所有能操作出的平面图的染色数之和。
手玩 $n \le 4$ 的所有情况,可以以 $O(1)$ 时间复杂度优雅地通过子任务 $1$,得到 $5$ 分的好成绩。
算法二
有染色就有对偶图。不妨从 $m = n - 1$ 开始研究,每次铺设操作会将一块区域分为两块,反过来,整个对偶图即两侧对偶图加上若干条边。根据新生成的接口后续是否被使用,讨论三种情况:
- “二分”:两侧接口均不使用,则两侧对偶图一定是孤立点,加边后对偶图仅一条边。
- “三分”:有一个接口不使用,则该侧对偶图是孤立点,加两条边,给另一侧对偶图接了个三角形。
- “四分”:两侧接口均被使用,加两条边,相当于拼接两侧对偶图,中间形成了个四边形。
稍加归纳,我们得出 $m = n - 1$ 的对偶图应是三角四边剖分图,即,三角剖分图去掉等于“四分”数量的边。
进一步地,$m < n - 1$ 时单独考虑某个道路连通块对偶图同上,现 $n - m$ 个连通块会共用区域,整个对偶图即各个对偶图通过 $n-m-1$ 对共用点合成的图。
显然,用 $k$ 种方式固定一个点的颜色后,$n$ 边形三角剖分图的染色方案数等于 $(k-1)(k-2)^{n-2}$,与剖分细节无关。每因“四分”去掉一条边,便少计算了两个点同色的情况,染色方案数只需乘上 $r = 1 + \frac{k-1}{(k-2)^2}$。而每多一个连通块,相当于固定共用点的颜色,其余和上面无差别。写出来就是 $k \prod (k-1)(k-2)^{s}r^t$,$s$ 为连通块大小,$t$ 为“四分”个数。
故暴力枚举所有能操作出的平面图,用上式统计答案,可以通过子任务 $1$ 与子任务 $2$,得到 $15$ 分。
算法二点五
我们希望找到一种对应关系,能够描述操作结果而不计过程,从而使计数不重不漏。注意到操作不改变空接口的数量,由此想到为初始的接口顺次标号 $1 \sim n$,每铺设道路,新生成的接口按顺时针方向继承消耗的接口的编号,从而使空插槽永远有各自的编号。考虑构建一棵操作树(森林):圆上顺次排布 $1 \sim n$ 号点,每继承了编号 $i,j$,给点 $i,j$ 间连边。圆上的区域一一对应原平面图的区域,因此连边不于圆内相交。
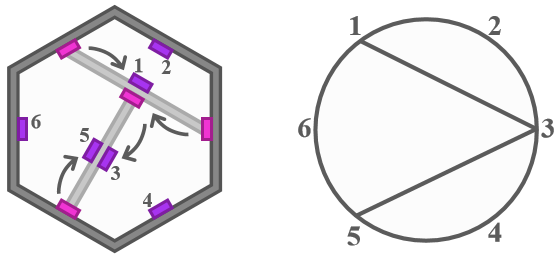
那么任意时刻的操作局面,都能映射为边不交叉的操作树(森林)。这是否构成双射?答案是肯定的。圆上连边情况亦可实现反推,对于圆上点 $i$,按照 $i-1,\ldots,1,n,\ldots,i+1$ 顺序寻找与之连边的 $j$,指针指向第一个找到的 $j$。显然存在一对 $i,j$ 互指向对方,那么便确定了一次铺设操作,$i,j$ 的指针分别指向下一个,如此反复。
由算法二的式子得知,“四分”是影响最终局面染色的关键,我们需要迁移“四分”的定义至操作树(森林)上。回顾后发现,编号为 $i$ 的空接口所在的道路一定不为“四分”,而这条道路正是圆上按照 $i-1,\ldots,1,n,\ldots,i+1$ 顺序与最后一个找到的 $j$ 间的边。对于所有 $i$,我们同时标记 $i$ 与对应 $j$ 间的边,“四分”数等价于未被标记的边数。
算法三
该算法是出题人最原始的做法,但是与正解相差甚远,有需要者请跳到算法 4!之所以单独列出,是因为该算法同样极具趣味性。
还是从 $m=n-1$ 开始。若未被标记的边数为 $t$,不妨分别列出满足条件的操作树数量的表达式,核心思想是:先不考虑圆,直接枚举树的结构(称未被标记的边为“桥边”,其将树划分成 $t+1$ 块,故先枚举各块缩点后桥边构成的树,再枚举各块内的树及桥边的分配),计算有多少于圆上排列的顺序使得边不交叉,最终总和除以 $n!$。
将块编号为 $0 \sim t$,块内点是有序的,确定以下关键量:
- $A=[a_0,\ldots,a_t]$ ($a_i\ge 1$, $n=\sum_i a_i$):表示第 $i$ 个块的点数
- $B=[b_0,\ldots,b_t]$ ($b_i\ge 1$, $2t=\sum_i b_i$):表示第 $i$ 个块缩点后的度数,即连接的桥边数
- $D_i=[d_{i,1},\ldots,d_{i,j}]$ ($d_{i,j} \ge 1$, $2a_i-2=\sum_j d_{i,j}$):表示第 $i$ 个块内各点的度数,不计桥边
- $P_i=[p_{i,1},\ldots,p_{i,j}]$ ($p_{i,j} \ge 0$, $b_i=\sum_j p_{i,j}$):表示第 $i$ 个块内各点被分配到的桥边数
分配标号,系数为 $\frac{n!}{\prod_i a_i}$。使用 Prufer 序列计数缩点后树的形态,系数为 $\frac{(t-1)!}{\prod_i (b_i-1)!}$。
考虑第 $i$ 个块内的贡献。计数块内树的形态,系数为 $\frac{(a_i-2)!}{\prod_j (d_{i,j}-1)!}$ 。分配桥边,系数为 $\frac{b_i!}{\prod_j p_{i,j}!}$。各点需要标记一条块内边,不论树形态如何,一定恰有一条边被标记两次,系数为 $a_i-1$。
接下来是最重要的圆上排列部分。在 CF1172B - Nauuo and Circle 中,我们知道排列方案数等于各点度数的阶乘之积乘上 $n$ 。在本题中,由于各点都有标记的边,其在排列时固定会把标记的边放在最旁边,因此贡献并非 $(d_{i,j}+p_{i,j})!$,而是 $(d_{i,j}+p_{i,j}-1)!$。
最终总和乘上上述结论的 $n$,除以 $n!$,注意块之间实际无序,还应再除以 $(t+1)!$,得到以下计算式:
$$\frac{n}{n!(t+1)!}\sum_A{\frac{n!}{\prod_i a_i!}}\sum_B{\frac{(t-1)!}{\prod_i (b_i-1)!}}\prod_i\left(\sum_{D_i}\sum_{P_i}\frac{(a_i-2)!}{\prod_j (d_{i,j}-1)!}\frac{b_i!}{\prod_j p_{i,j}!}(a_i-1)\prod_j{(d_{i,j}+p_{i,j}-1)!}\right)$$
我们先作一些初等的简化:
$$\frac{n}{t(t+1)}\sum_A\sum_B\prod_i\frac{b_i}{a_i}\left(\sum_{D_i}\sum_{P_i}\prod_j{\frac{(d_{i,j}+p_{i,j}-1)!}{(d_{i,j}-1)!p_{i,j}!}}\right)$$
看似无法再推下去,但有趣的是,括号内的式子存在组合意义。将分式写成组合数 $\binom{d_{i,j}+p_{i,j}-1}{d_{i,j}-1}$,其表示 $d_{i,j}-1$ 个黑球,$p_{i,j}$ 个白球的排列方案数。$a_{i}$ 个点对应 $a_i-1$ 个隔板,黑球共 $\sum_j {d_{i,j}-1} = a_i-2$ 个,白球共 $\sum_j {p_{i,j}}=b_i$ 个,括号内等价于求隔板、黑球、白球的排列方案数,即 $\binom{2a_i+b_i-3}{a_i-1,a_i-2,b_i}$。
于是原式可再度简化为:
$$\frac{n}{t(t+1)}\sum_A\sum_B\prod_i \frac{(2a_i+b_i-3)!}{a_i!(a_i-2)!(b_i-1)!}$$
里面还是三项式系数。我们如法炮制,$t+1$ 个块对应 $t$ 个隔板,黑球共 $\sum_i a_i=n$ 个,灰球共 $\sum_i a_i-2=n-2t-2$ 个,白球共 $\sum_i b_i-1=t-1$ 个。然而黑球、灰球都与 $a_i$ 有关,难以直接统计排列方案,但我们仍可以提取出白球,也即:
$$\frac{n}{t(t+1)}\binom{2n-3}{t-1}\sum_A\prod_i \binom{2a_i-2}{a_i}$$
现在试图表示总答案。令 $l = k(k-1)(k-2)^{n-2}$, $C(x)=\sum_{i=2}^{\infty} \binom{2i-2}{i} x^i$,则有:
$$\text{ans}=l\sum_{i=0}^{n}\frac{n(2n-3)!}{(i+1)!(2n-i-2)!} \left([x^n] C(x)^{i+1}\right)r^i$$
奇迹般地,我们整理出二项式系数,对上式作最后的化简:
$$\text{ans}=\frac{nl}{(2n-2)(2n-1)r}[x^n]\sum_{i=0}^{n}\binom{2n-1}{i+1} (rC(x))^{i+1}=\frac{nl}{(2n-2)(2n-1)r}[x^n](1+rC(x))^{2n-1}$$
实现多项式快速幂即可,时间复杂度 $O(n \log n)$,期望通过子任务 $3 \sim 6$,得到 $40$ 分。结合算法二,期望得到 $55$ 分。
算法四
算法三的遗憾在于只能求单点,而难以批量处理所有 $n=1 \ldots N $ 的 $m = n - 1$,看来我们对问题的理解还未到达本质。下面将再运用一个经典双射,将题意演变成容易解决的传统多项式问题。
不妨钦定操作树的 $1$ 号点为根,点 $i$ 的子结点 $j$ 分两类:
- L 儿子:$j < i$,即在圆上 $j$ 位于 $i$ 的逆时针方向。
- R 儿子:$j > i$,即在圆上 $j$ 位于 $i$ 的顺时针方向。
然后我们构造一棵三叉树,各点的三叉具体包含:
- 一或零条 / 边:连接第一个 L 儿子,若无 / 边则无 L 儿子。
- 一或零条 | 边:连接第一个 R 儿子,若无 | 边则无 R 儿子。
- 一或零条 \ 边:若自己是某个点第 $x$ 个 L 儿子,则连接其第 $x + 1$ 个 L 儿子,否则连接其第 $x + 1$ 个 R 儿子,若无 \ 边则自己其是最后一个 L 或 R 儿子。
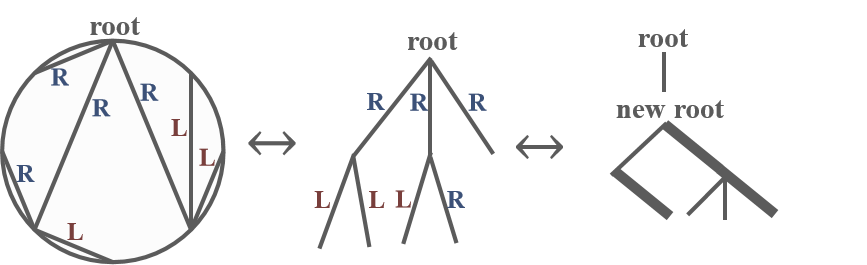
由于原根结点 $1$ 的儿子一定均为 R 儿子,所以三叉树上其一定仅有 | 边。我们不妨删之,用 | 边连接的儿子作为新的根结点。于是我们成功将 $n$ 个点的操作树对应到了 $n-1$ 个点的三叉树。反推以上过程,不难发现二者形成双射。
下一步自然是再次迁移“四分”的定义。显然,圆上每个点的标记规律是:若有 R 儿子,标记与第一个 R 儿子间的边,若无 R 儿子,则标记父边。那么三叉树上一条边欲代表“四分”,首先自身不能是 | 边,否则会被父结点标记,其次子结点必须有 | 边,否则会被子结点标记。也即,“四分”数等价于三叉树符合以下结构的边的子集数:

于此多项式的引入便不言而喻了。定义一个三叉树的权值为 $r$ 的“四分”数次方,$F(x)$ 表示不同大小的所有三叉树的权值和,$G(x)$ 表示不同大小的根结点无 | 边的三叉树的权值和,则有:
$$\left\{\begin{aligned}F(x)&=1+F(x)(G(x)-1)\\G(x)&= 1+x\left(G(x)+r(F(x)-G(x))\right)^2\end{aligned}\right.$$
稍加化简可得:
$$r^2 xF(x)^4+(4-4r) xF(x)^3+((6r^2-10r+4)x-1)F(x)^2+((4-4r)(r-1)x+1)F(x)+(r-1)^2x=0$$
套用经典的牛顿迭代即可。时间复杂度 $O(n \log n)$,同样期望得到 $40$ 分。
实际上,若将算法三中的 $\binom{2i-2}{i}$ 解读为二叉树计数,正是 $F(x)$ 的某种展开。我们只是从另个方向上,更为宏观地解读了 $F(x)$。另外,在 127 群友的指点下,朴素精妙的 dp 设计能直接跳过算法二点五导出类似的三叉树结构,正确性也得到了验证。
算法五
从 $m=n-1$ 到 $m < n-1$ 的实际瓶颈在于,操作森林有多少种圆上排列方式,使得多个连通块的操作树间边不交叉。
惊人结论是,排列方案数等于 $n^{\underline{m-1}}=\frac{n!}{(n+1-m)!}$,与各连通块的大小无关。首先破环成链,设连通块大小分别为 $a_1, \ldots, a_m$,同时,我们临时加入 $a_0 = 2$,将其置于链的两端。考虑构建一棵包含关系树:各连通块代表的点的父结点为在包含自己的极小连通块。包含关系树的结构数可在枚举度数后用 Prufer 序列计算,而对于大小为 $a_i$ 的连通块,需要在其间插入 $j$ 个带标号的儿子,系数显然为 $\binom{a_i-2+j}{j}j!$。由此列得:
$$
(m-1)![x^{m-1}]\left(\sum_{j=0}^{+\infty}\frac{\binom{j+1}{j}j!}{j!}x^j\right)\prod_{i=1}^{m}\sum_{j=0}^{+\infty}\frac{\binom{a_i-2+j}{j}j!}{j!}x^j
$$
运用生成函数化简即证:
$$
(m-1)![x^{m-1}]\frac{1}{(1-x)^2}\prod_{i=1}^m\frac{1}{(1-x)^{a_i-1}}=(m-1)![x^{m-1}]\frac{1}{(1-x)^{n-m+2}}=(m-1)!\binom{n}{m-1}=\frac{n!}{(n+1-m)!}
$$
因此我们实现多项式快速幂,求单个连通块答案多项式的 $n-m$ 次方,取出第 $n$ 项乘上一定系数则为答案。
时间复杂度 $O(n \log n)$,可以通过全部子任务,期望得分 $100$ 分。
另解
下面为 zhoukangyang 所分享的 B 题题解: https://www.cnblogs.com/zkyJuruo/p/17136175.html 。在此表达感谢!
另·另解
下面为 hos_lyric 所分享的 B 题题解: https://hos-lyric.blog.uoj.ac/blog/8415 。在此表达感谢!
idea, data, solution, std from 127
算法一
对于第一个子任务,使用暴力 BFS 计算点对间距离。
时间复杂度为 $O(nq)$,期望通过子任务一,得到 $5$ 分。
算法二
按照路径经不经过根进行分类讨论,距离即为曼哈顿距离。
期望通过子任务二,得到 $8$ 分。结合算法一可得到 $13$ 分。
算法三
对于第三个子任务,可以使用沿中线分治/线段树维护矩乘的方法解决。
期望通过子任务三,得到 $10$ 分。结合算法一、二可得到 $23$ 分。
算法四
对于第四个子任务,图等价于网格图,按任意行列切开均可,如果想要刨去根,只需先对根做一次bfs,再算经过根对答案的贡献即可
期望通过子任务二、三、四,得到 $45$ 分。结合算法一可得到 $50$ 分。
算法五
原本四年前出的这题,直到找到了separator theorem才发现可做。
可以认为是平面图最短路Oracle,存在更优的做法,而像是有时遇到的像高分子聚合物一样的图都可以使用。
按照separator theorem的想法,我们要去找尽可能优的separator,但是此图有一个好处,即bfs树就是原树。
因此我们可以获取很大的便利。
首先若树高不超过$\sqrt{n}$,我们可以竖着劈一刀,具体来说,我们先找到处于dfs序中间的点,其到根的路径将树分为左右,且非常平均,但是我们知道这并没有分开整棵树(即使这个点是叶子,由于有横向边,其下方也有可能穿过),于是我们不断找到$dfs$序上的下一个比当前点的深度要大的点,然后选择其到根的链上比当前点深度要大的部分合并到separator中。
考虑为什么这样是separator,在dfs序上,这些点将序列分为很多个部分,则每两个部分之间的点的深度的max在所选的separator中取到,则跨过最初的中位点的到根链的部分之间的所有深度被separator取到,即一定会经过我们选择的separator。
若树高高于$\sqrt{n}$,我们按照separator theorem的方法去选择,具体的按层算出每层$siz_i$,找到其前缀和的中位数$p$,其在第$mid$层,并向前向后找到$l,r$满足条件$siz_l+mid-l\leqslant 2\sqrt{p},siz_r+r-mid\leqslant 2\sqrt{all-p}$。
然后我们中间的设计不按照原定理去做,按照我们上面所述的树高不高的方法做即可。
找到了separator我们按照其分裂原图,分治下去,并计算经过这些点的最短路贡献答案。
时间复杂度是$T(n)=2T(\frac{n}{2})+O(n\sqrt{n})=O(n\sqrt{n})$。
不过这样可能会导致一些问题,比方说其实我们当前分治到的部分不是一个原树上的连通块,而应当用很多个原树上的连通块及其之间的横边表示,需要进行一些处理。
多使用vector进行找separator的过程会好写,不是瓶颈。
期望通过所有子任务,得到 $100$ 分。
算法六
实际上,笔者观察到选手所写的代码,发现非常有道理。
这是因为,实际上separator定理在本题中不需要是一整个separator,也就是分成三部分完成separator的构造,只不过三次取的界限应当比较一致。
因此简单认为每次只分横竖都是有道理的。
期望通过所有子任务,得到 $100$ 分。

 鄂公网安备 42010202000505 号
鄂公网安备 42010202000505 号